Recipe 007
Claude Fable 5 vs Opus 4.8: What the New Top Model Actually Buys You
Anthropic's new flagship sits in a tier above Opus — at double the price. We charted the benchmarks against Opus 4.8, and the pattern is clear: the harder the task, the wider the gap. Here's what that means for what you cook.
On June 9, 2026, Anthropic shipped Claude Fable 5 — the first model in the Claude 5 family, and the first of a new Mythos-class tier that sits above Opus. Not "Opus 5." A new shelf entirely, priced to match: $10 per million input tokens and $50 per million output — exactly double Opus 4.8's $5/$25.
Double the price demands an answer to one question: what do you actually get? We put the numbers side by side.
First, the odd name
Fable comes from the Latin fabula — "that which is told" — the Latin cousin of the Greek mythos. The two names are the same underlying model with different safety configurations: Fable 5 is the generally available version and carries extra safeguards for dual-use domains (it declines certain biology and cybersecurity requests, and on most consumer surfaces those requests quietly fall back to Opus 4.8 instead of failing). Mythos 5 runs without those restrictions and is only available to approved organizations. For everyone reading this: Fable 5 is the flagship you can touch.
The benchmarks, charted
We compared Anthropic's reported scores for Fable 5 and Opus 4.8 across five benchmarks — from a well-worn industry standard to the newest, meanest evaluations available:
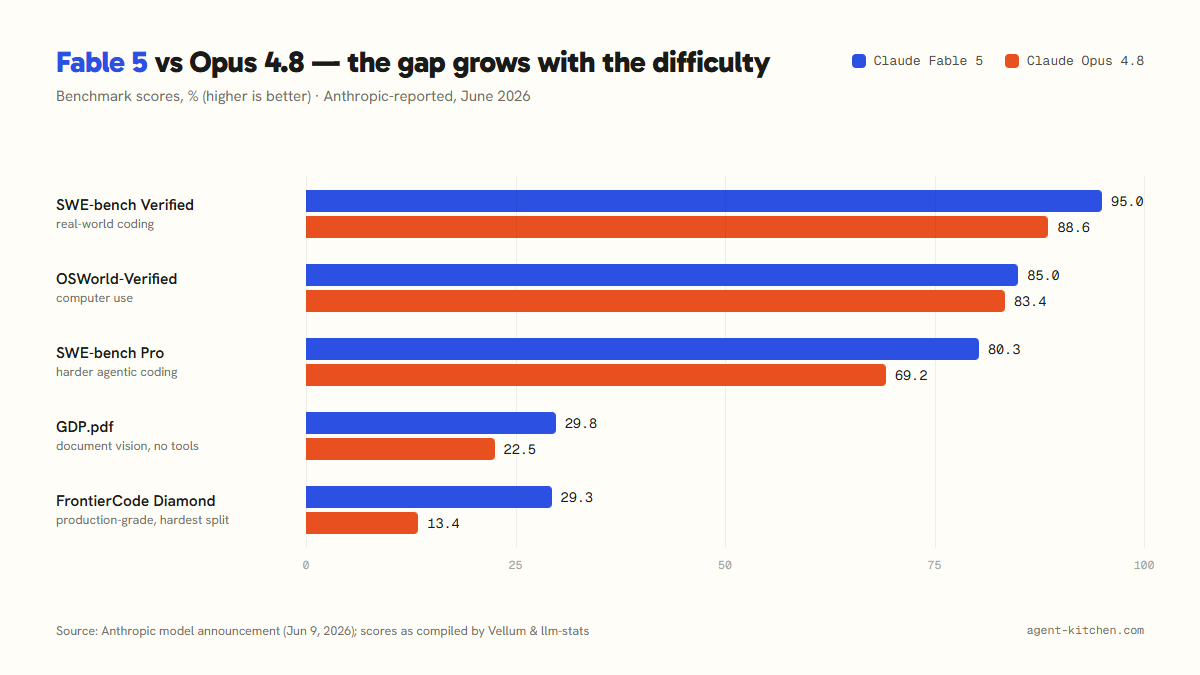
What each row means, in kitchen terms:
- SWE-bench Verified — fixing real bugs from real GitHub repos. The industry's favorite coding test, and by now nearly saturated: 95.0 vs 88.6.
- OSWorld-Verified — using a computer like a human: clicking, typing, navigating real apps. Nearly a tie (85.0 vs 83.4).
- SWE-bench Pro — the harder successor to Verified, built to resist memorization. The gap widens: 80.3 vs 69.2.
- GDP.pdf — reading dense, messy real-world documents with no tools allowed, just eyes. 29.8 vs 22.5.
- FrontierCode (Diamond) — the hardest split of a new benchmark that grades code the way a senior engineer at a real company would. 29.3 vs 13.4 — more than double.
The pattern that matters
Read the chart top to bottom and the story writes itself: on tasks the previous generation already handled well, Fable 5 buys you a few points. On tasks at the frontier of what AI can do at all, it buys you twice the model.
That's not an accident — it's the whole positioning. Anthropic's own framing is that Fable 5's gains concentrate on long-horizon work: tasks that take an agent hours and hundreds of steps, where a small per-step advantage compounds into finishing-versus-not-finishing. A single Fable 5 request on a hard problem can run for many minutes, thinking is always on (you literally cannot turn it off via the API), and it's markedly better at using persistent memory across sessions.
So which one goes in your kitchen?
Honest answer for most readers of this blog: Opus 4.8 is still the workhorse, and it's excellent. It scores within a few points of Fable 5 on everyday coding, costs half as much, and is snappier on quick tasks. If your prompts finish in seconds and your projects fit in an afternoon, you will barely feel the difference.
Reach for Fable 5 when the job looks like this:
- Long-horizon runs — "refactor this whole module and don't stop until the tests pass," overnight agent sessions, multi-hour research.
- The hard 10% — the task Opus attempted twice and fumbled twice. That FrontierCode gap (13.4 → 29.3) is exactly this category, measured.
- Dense document work — contracts, filings, scanned PDFs, where the GDP.pdf gap shows up in practice.
And a budget note: since output tokens dominate agent costs, a Fable 5 session costs roughly 2× the same session on Opus — not 10×. For a task you'd otherwise retry three times on a cheaper model, the math can actually favor the expensive one that gets it right once.
If you use Claude Code, switching is one command: /model, pick Fable 5, cook. (Availability depends on your plan — check the picker.)
Full disclosure, because this kitchen practices what it preaches: the agent that researched, charted, and drafted this post runs on Fable 5. The benchmark chart above? It built that too.
Order up
Want to feel the difference instead of reading about it? Take the hardest thing your agent failed at recently and paste this:
Here's a task a previous AI model attempted and failed: [describe the task and what went wrong].
Before touching anything: analyze why an earlier attempt likely failed, list the
constraints that make this hard, then plan and execute. Take your time — I care
about it being right, not fast. Verify your own result before reporting done.
Run it once on your usual model, once on Fable 5, and compare. On easy tasks you'll shrug. On the right task, you'll see what the top shelf is for.
Scores are Anthropic-reported figures from the June 2026 announcement, as compiled by Vellum and llm-stats. Benchmarks measure narrow slices of ability — treat them as a menu, not a verdict.