Recipe 008
GPT-5.6 Sol, Terra, and Luna: What's Real, What's Locked, and What It Means for Your Kitchen
OpenAI's new model family is named after the sun, the earth, and the moon — and you can't use it yet. Here's the fact-checked rundown: the three tiers, the prices, the one benchmark chart that matters, and why the release itself is the biggest story.
On June 27, 2026, OpenAI previewed GPT-5.6 — not one model but three, named Sol, Terra, and Luna. The sun, the earth, the moon. (Crypto veterans immediately noticed that's also two token tickers and one of the most infamous collapses in crypto history sharing a product line. The jokes wrote themselves; OpenAI, presumably, was aiming for the solar system.)
Naming comedy aside, there's real substance here — and one plot twist about who's allowed to use it. Here's what we could verify.
Three tiers, one sensible naming scheme
The genuinely good idea in this launch: the number is the generation, the name is the tier. GPT-5.6 Sol, Terra, and Luna are one generation in three sizes, and each tier can advance on its own schedule. After years of model names that read like license plates, this is the kind of clarity worth stealing.
| Tier | Positioning | Price (per 1M tokens, in/out) |
|---|---|---|
| Sol | Flagship — hardest problems, complex coding, research. Gets max reasoning and a new ultra mode |
$5 / $30 |
| Terra | The workhorse — business tasks, support, document analysis. Roughly GPT-5.5-level at about half the price | $2.50 / $15 |
| Luna | Fastest and cheapest — summarization, drafting, high-volume automation | $1 / $6 |
The most interesting line item is ultra mode: Sol can spin up subagents to accelerate complex tasks — orchestration that used to be your harness's job (the pattern Claude Code users know well) now productized inside the model API itself.
The one chart worth looking at
OpenAI's headline numbers center on Terminal-Bench 2.1, which tests agentic work in a real terminal — close to what vibe coders actually do all day. Here's the family against its own previous generation:
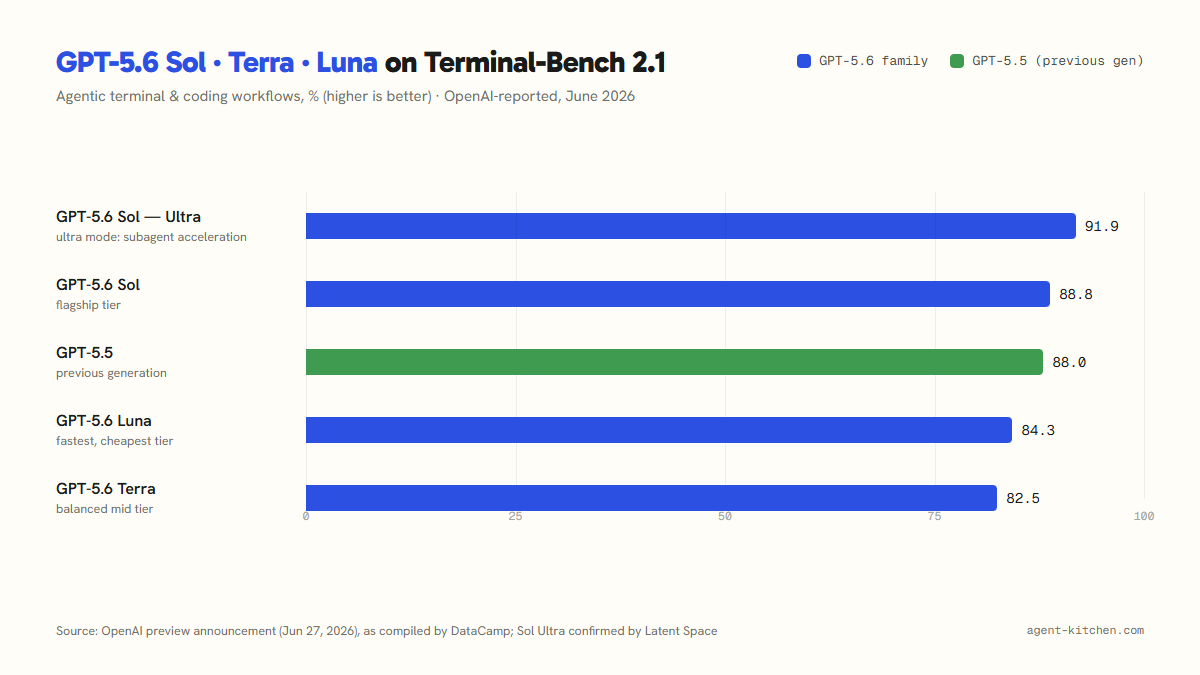
Three honest readings of that chart:
- The frontier moved less than the marketing suggests. Plain Sol beats GPT-5.5 by 0.8 points on this benchmark. Ultra mode's subagent trick is what produces the headline 91.9.
- The cheap tiers are the story. Luna at 84.3 and Terra at 82.5 land within a few points of last generation's flagship — at a fraction of the cost. Terra is reportedly the first "flash-sized" model to clear 80 on this benchmark. For high-volume work, that's the number that changes budgets.
- Efficiency is the quiet headline. OpenAI repeatedly claims better results with fewer tokens — on one cybersecurity eval, about a third of the output tokens of a comparable frontier model. Since you pay by the token, efficiency gains are effectively a second price cut.
What about cross-vendor comparisons — GPT-5.6 vs Claude, vs Gemini? OpenAI's chart places its family favorably, as vendor charts always do. Third-party compilations disagree with each other on the exact competitor numbers, so we're not charting those: treat any cross-vendor row you see this week with a pinch of salt until independent evals land.
The plot twist: you can't use it yet
Here's the part that would have sounded like science fiction two years ago: GPT-5.6 launched at the request of the U.S. government into a limited preview — roughly twenty government-approved companies get access through the API and Codex, with broader availability promised "in the coming weeks."
If that pattern sounds familiar, it should: we covered Anthropic gating its unrestricted Mythos 5 behind approved-organization access two posts ago. Staged, safety-gated releases are becoming the standard playbook for frontier models, not the exception. The era of "everyone gets the new model on launch day" appears to be ending — at least at the very top shelf.
For ChatGPT and Codex subscribers, the practical takeaway: nothing changes today. When the rollout widens, expect Terra to quietly become the default that most requests route to, Luna to power the fast paths, and Sol to sit behind the highest plan tiers — that's the economics the pricing table implies. (A blistering 750-tokens-per-second version of Sol hosted on Cerebras hardware is slated for July, initially for select customers.)
Cook with what's on the counter
Our standing advice doesn't change: the model you have access to today, driven well, beats the model you're waiting for. If you set up Codex with your ChatGPT subscription, GPT-5.5 is still excellent — and when 5.6 lands in your picker, you'll be switching one dropdown, not relearning anything.
Order up
The most useful thing you can do before any new model arrives: build your personal benchmark. Vendor charts measure their tasks; you should measure yours. Paste this into your agent today:
Help me build a personal model benchmark. Create a file called my-bench.md with:
1. Three tasks from my recent work that today's AI models handled poorly or needed
several retries on — ask me questions to reconstruct them precisely.
2. For each task: the exact prompt to run, and a checklist of what a correct
result must contain.
Keep it short enough to run in 15 minutes. When a new model comes out, I'll run
all three and compare against these notes.
When GPT-5.6 — or the next Fable, or whatever ships next month — finally lands in your picker, you'll know within fifteen minutes whether it matters for you. That beats any launch chart, including ours.
Figures are OpenAI-reported numbers from the June 27, 2026 preview announcement, as compiled by DataCamp and Latent Space. Benchmarks are narrow slices — a menu, not a verdict.